The Data Science Task Force
“We’ll send a task force with you.”
―Jedi Master Mace Windu advises Master Obi-Wan Kenobi
0 背景介绍
2017年8月,ACM教育理事会上,成立了一个数据科学特别工作组(Task Force),探讨关于增加对数据科学的广泛、跨学科的对话,以及计算学科对这一新兴领域的贡献和承担的角色。
特别工作组于2019年1月发布了第一版面向高等教育的数据科学课程体系的胜任力[1]报告(Computing Competencies for Undergraduate Data Science Curricula)的初稿,2019年12月,更新了初稿第二版(Draft 2),在前一版的基础上重新定义、规划并细化了“知识领域”(Knowledge Areas),增加了T1(Tier 1)、T2(Tier 2)和选修(Elective)三个级别的知识、技能和品格,增加了部分章节:参与范围、构建计划和制度挑战[2]。
草案主要内容包括:
- 宗旨和目标
- 现状的前期工作
- 数据科学的主体知识
- 根据课程建议构建课程计划
- 扩大参与范围
- 学员的个性和品格
- 制度挑战
工作组的成员中有两位中国大学的教授:华东师范大学的钱卫宁和哈尔滨工业大学的王宏志,另外有USA10人、UK1人和Canada1人。
同IT2017类似,这不是一套规章制度,其内容也不具有强制性,但是对相关领域具有十分重要的意义和指导作用。参考IT2017的定位,一方面对数据科学专业人才培养的定位和具体课程体系的设置具有十分重要的指导,另一方面强调基于胜任力模型的学习过程和课程体系开发,全面的对知识体系按照学习成效进行了梳理、补充和完善,适应了工程认证、专业评估的要求。因此帮助并指导学校、科研机构、企业组织能够更规范地、更有条理地制定相关的知识培养计划、技术发展规划和人才招募标准。
1 数据科学的现状
数据的本质是现实世界运转的映射,人类通过发现、观察、测量、分析这些数据,才能理解、改造和影响现实世界。从现实世界到数据时描述、归纳、抽象成数据模型的过程,从数据到现实世界是用模型来预测、推断的过程,这是一个闭环,数据科学就是实现这个闭环的自动化、智能化的技术,让循环不断优化。
2001年,数据科学作为一个独立的学科提出,2007年,著名计算机科学家吉姆格雷就指出“数据密集型科学”已经成为继实验、理论、计算模拟之后的第四科学研究范式。
数据科学本质上是一个交叉学科,其兴起与各领域日益增长的海量数据直接相关。科学、社会学、商业、人文、工程都渴求从前所未有的大数据中探寻潜在的创新机遇和决策依据。数据科学即是这样一个综合利用领域数据、计算科学和统计工具来探查数据获得有用信息的交叉学科,这是一个非常具有挑战性的工作。
早期对于数据科学的体系梳理包括:
- The EDISON Data Science Framework(2018)
- The National Academies of Science, Engineering, and Medicine Report on Data Science for Undergraduates(2018)
- The Park City Report(2017)
- The Business Higher Education Framework (BHEF) Data Science and Analytics (DSA) Competency Map(2016)
- Business Analytics Curriculumn for Undergraduate Majors(2015)
- Initial workshops related to this ACM Data Science Curriculumn effort(2015)
随着IoT、复杂传感器、人脸识别、语音识别、自动化技术的迅猛发展,计算机技术举足轻重,基于大数据的分析、处理和机器学习、人工智能等方面的投入将为领域学科带来丰厚的回报。
2 胜任力模型(The Competency Framework)
草案中定义的胜任力(Competency)遵循ACM/IEEE-CS IT2017的框架体系。
胜任力指的是专业或业界权威机构相关的绩效评价标准,工作中被用于评估胜任力的等级,是人们展现优秀工作表现所依托的内在品质。业界广泛认同的胜任力包含以下三个维度:知识(Knowledge)+技能(Skills)+品行(Dispositions)。
- 知识代表对核心概念与内容的熟练程度以及在新环境中的学习和应用能力;
- 技能是长期实践以及与他人和世界的交互中发展和培养出来的责任感与策略。也要求在高级认知行为中的投入,“动手”的技能实践要与“动脑”相结合;
- 品行包含社会情感技能、行为准则和礼仪态度,表现为执行任务的倾向以及对何时和如何从事这些任务的敏感性。
每个知识领域都会使用一套胜任力模板来描述,模板如下: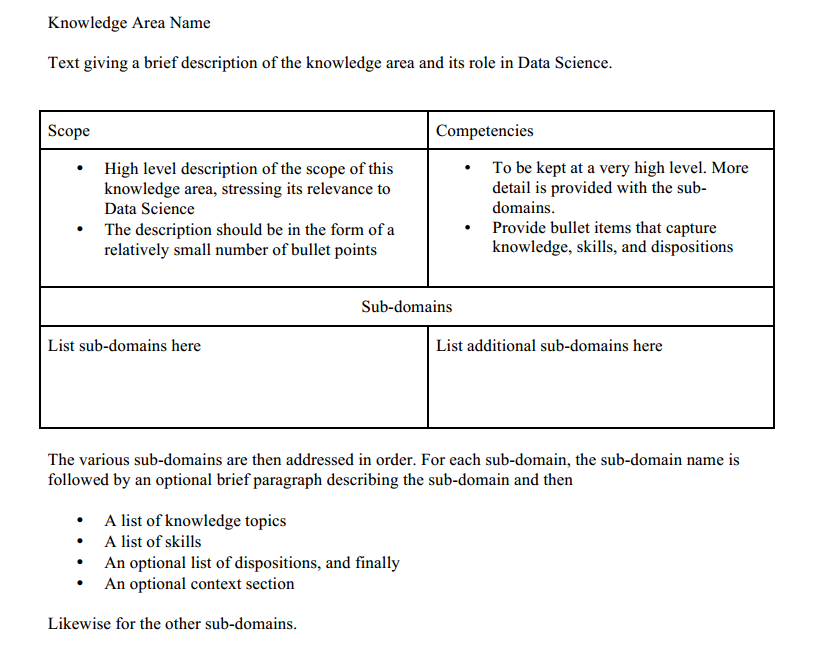
对于每个子领域(sub-domain)都会详细描述其所需掌握的知识、技能和素养,这些内容都有一个额外的标注T1、T2和E代表其所需要掌握的程度:
- T1(Tier 1):表示每一个学员都必须掌握(mastered);
- T2(Tier 2):表示期望大多数据学员都掌握,且每个学员都至少掌握该项目的主要知识;
- E(选修,Elective):可选修的部分。
3 数据科学的知识领域(KA,Knowledge Areas)
数据科学的计算机知识领域包括:
- 分析和展示(AP,Analysis and Presentation)
- 人工智能(AI,Artificial Intelligence)
- 大数据系统(BDS,Big Data Systems)
- 计算和计算机基础(CCF,Computing and Computer Fundamentals)
- 数据获取、管理和治理(DG,Data Acquisition,Management,and Governance)
- 数据挖掘(DM, Data Mining)
- 数据隐私和安全(DP,Data Privacy,Security,Integrity,and Analysis for Security)
- 机器学习(ML,Machine Learning)
- 专业素养(PR,Professionalism)
- 编程、数据结构和算法(PDA,Programming,Data Structures,and Algorithms)
- 软件开发和维护(SDM,Software Development and Maintenance)

4 个人素养(Characteristics)
除了上述知识领域以外,数据科学学员还需要培养如下素养和特质,帮助自己的相关领域的工作和学习中获得成功。
- 基础数学、统计和计算机技能的预备知识,能够使用Python或R编写程序、具备使用常规库和学习新工具的能力,掌握使用数据库和因特网的技能,能够阅读论文,熟悉并使用公共数据集并用于理论知识;
- 乐于学习快速迭代的新知识,能够从经验中不断总结和发展;
- 对应用领域的广泛兴趣并具有一定的专业水平,理解业务任务和目标,发现挑战和基于;
- 关注和警惕非技术领域、人文领域的冲击和影响,例如个人隐私、信息安全等;
- 良好的沟通技能,聆听客户诉求,识别真实需求,学会问问题以及流畅的表达和沟通,包括制作最终的交付物和报告;
- 具有社会责任感、法律意识、伦理道德,了解区域文化差异。
5 数据科学人才
由于同时具备数学+计算机科学+领域知识的交叉型人才非常稀有,因此数据科学通常需要不同团队之间的协作,大致可以把数据人才分为以下几种类型:
数据技术人才
主要负责数据处理的全过程,即数据的获取、存储、清洗、加工、建模、传输和诠释,数据采集工程师、数据系统研发、应用研发、数据可视化工程师等都属于该类人才。
数据管理人才
主要负责对数据的保存、管理、维护和运营。面对“数据”这个特殊的管理对象,需要有能够适应这个特殊性的管理人才。
数据安全人才
主要负责对数据安全(包括数据本身和数据防护安全)的维护和保障,包括维护数据隐私、防止数据盗用和滥用、保护加密数据、阻止黑客攻击、建立数据安全防护体系等。
数据政策人才
只要负责数据相关的政策、法律及制度的研究。
数据科学家
狭义来说,数据科学家指能够利用数据作为资源,具有数据分析能力,精通各类算法,直接处理数据,创造附加价值的人才。
首席数据官CDO
CDO是数据如何收集、如何管理、如何应用的总指挥,为组织的数据收集、管理、分析、应用、安全等多个领域建立标准、设定方案并给出发展趋势,是制定数据战略、管理数据资产、建设数据队伍的综合型管理人才。
附:注解
[1]: 相关术语的中文翻译参照ACM中国教育委员会和教育部高等学校大学计算机课程教学指导委员会翻译的《信息技术课程体系指南2017》(IT2017),该指南同样由ACM和IEEE CS编制。
[2]: 来源Poster presentation at SDSS 2020, Virtual, June 2020