The Data Strikes Back
今天是双十二,我们来聊聊双十一。
1 “骗局”?
今年淘宝双十一之后阿里公布的销售额高达2684亿元,比去年增长25.7%。就在官方陶醉在历史新高、普罗大众沉浸在买买买的兴奋中时,有人挖出了早在当年4月份微博用户@尹立庆所发的《关于淘宝2009年-2018年历年双11销售额数据造假的消息》,文中利用简单的二次回归模型,成功预测了7个月后的销售数据,并质疑淘宝销售数据的真实性。
原博文已被删除,网页快照如下:

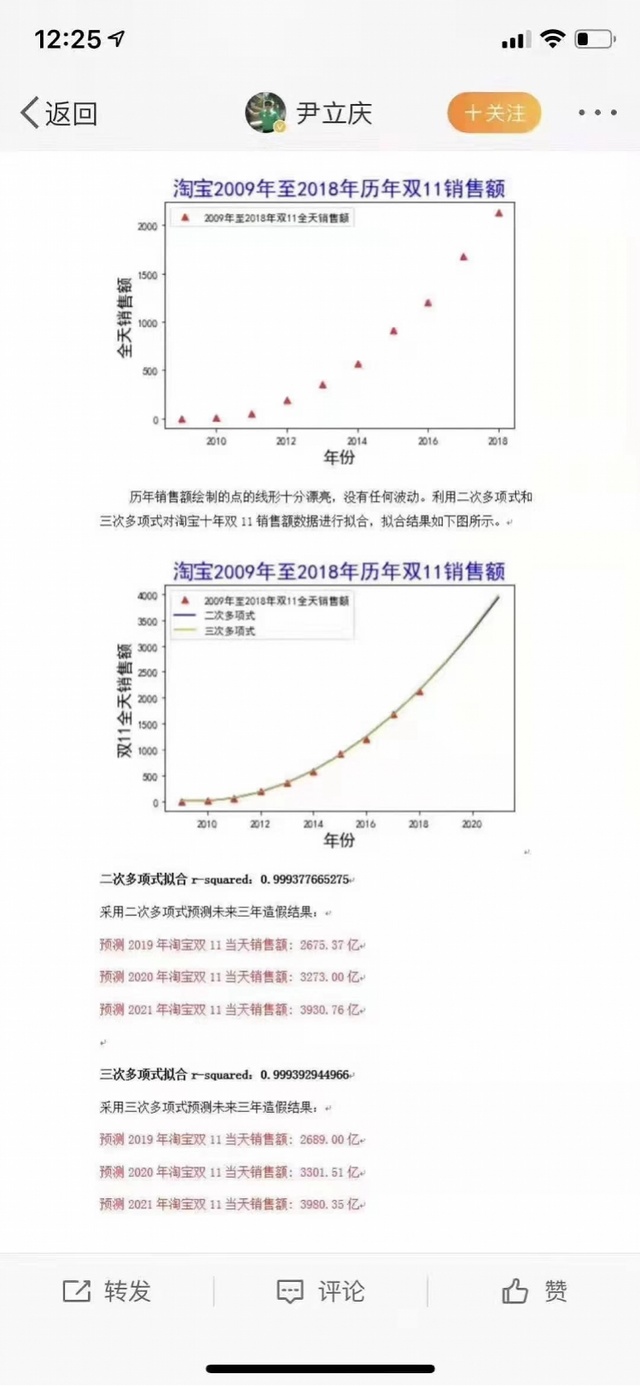
一时间网上争论纷纷,有人怀疑在拼多多挤占了市场的情况下是否真能有如此高的增长,反方有摆出“阴谋论”的认为是各种反华势力借此来质疑中国经济的虚假增长,等等。
2016年,已经有人对这提出过类似的质疑。

2 神预测还是过拟合
知乎上的问题《如何看待双十一销售额完美分布在三次回归曲线上且拟合高达 99.94%?是巧合还是造假?》中,很多人的回答都跑偏了,包括部分数学、统计学、经济学的公知大V们。
- 凡是拿冯·诺依曼的“四个参数画大象,五个参数甩鼻子”来解释的都是没有读懂题干,@尹立庆使用的是18年及以前的数据训练建模,来预测7个月后19年的销售额并且在验证集上达到了极高的准确度,说明这是一个非常优秀的模型。如果19年的实际数据与预测值差异非常大,那才是过拟合。
- 讨论R^2是三个9还是两个9,并引入其他数据如黑五和GDP来比较的,是偷换概念,作者质疑的是实际数据与预测数据差异非常小的小概率事件连续发生,而其他数据存在类似情况并不能反证这是正常的。事实上,用黑五的数据来做类似的预测,效果要差很多。
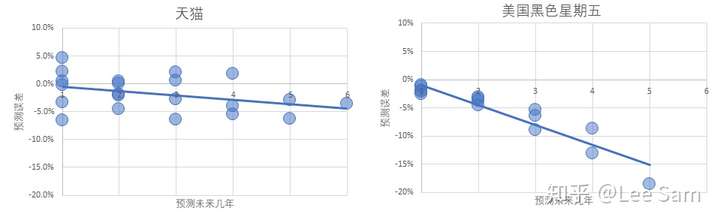
- 对于“造假”的理解,只有很少人提出看法。阿里不会愚蠢到直接修改一个最终结果,但是内部统计逻辑是不透明的,这就涉及到统计偏差。统计数据的偏差其实比我们想象的要普遍,比如国家统计局每年都会对GDP做核算和调整:国家统计局:修订后的2018年GDP为919281亿元。

GDP是一个非常复杂的统计数字,但是阿里计算销售额肯定要相对简单得多,这当中存在的猫腻应该主要不是计算逻辑,而是每笔交易的真实性和交易金额的水分。
- 销售金额中的水分可能存在的地方有:交易时间、交易金额、退货和取消交易,这些就为了营销活动的执行提供了可操作的空间。
3 背后的故事
中科院应用数学的博士(
https://www.cnbeta.com/articles/tech/909871.htm ) 指出了一个事实:如果计划就是这样制定的,那么执行团队会通过“各种手段”将KPI完成的八九不离十。
所以,故事可能是这样的:阿里负责制定KPI的团队制定了19年双十一的销售额指标,而且很可能就是使用二次或者三次回归模型(亦即@尹立庆的方法),然后运营部门层层分解,最终执行端想尽一切办法,压榨商户也好、提前预售也好、锁定购物车也好、延迟退货也好,最终确保完成了任务指标。
“原阿里集团安全研究实验室总监”的微博用户“安全_云舒”透露了部分细节:“阿里控住交易额很容易,通过数据分析找出最活跃的商品,然后通过增加或者减少这些商品投送,就能达到一个类似的预设目标,保持每年增长率,根本没必要伪造数据或者刷单。”

双十一后阿里股价平稳,并没有因为创历史新高而大幅提升,这个业绩并没有引起投资者的反应,或许阿里只是完成了自己的承诺,也可能大家都知道这并不能说明什么。
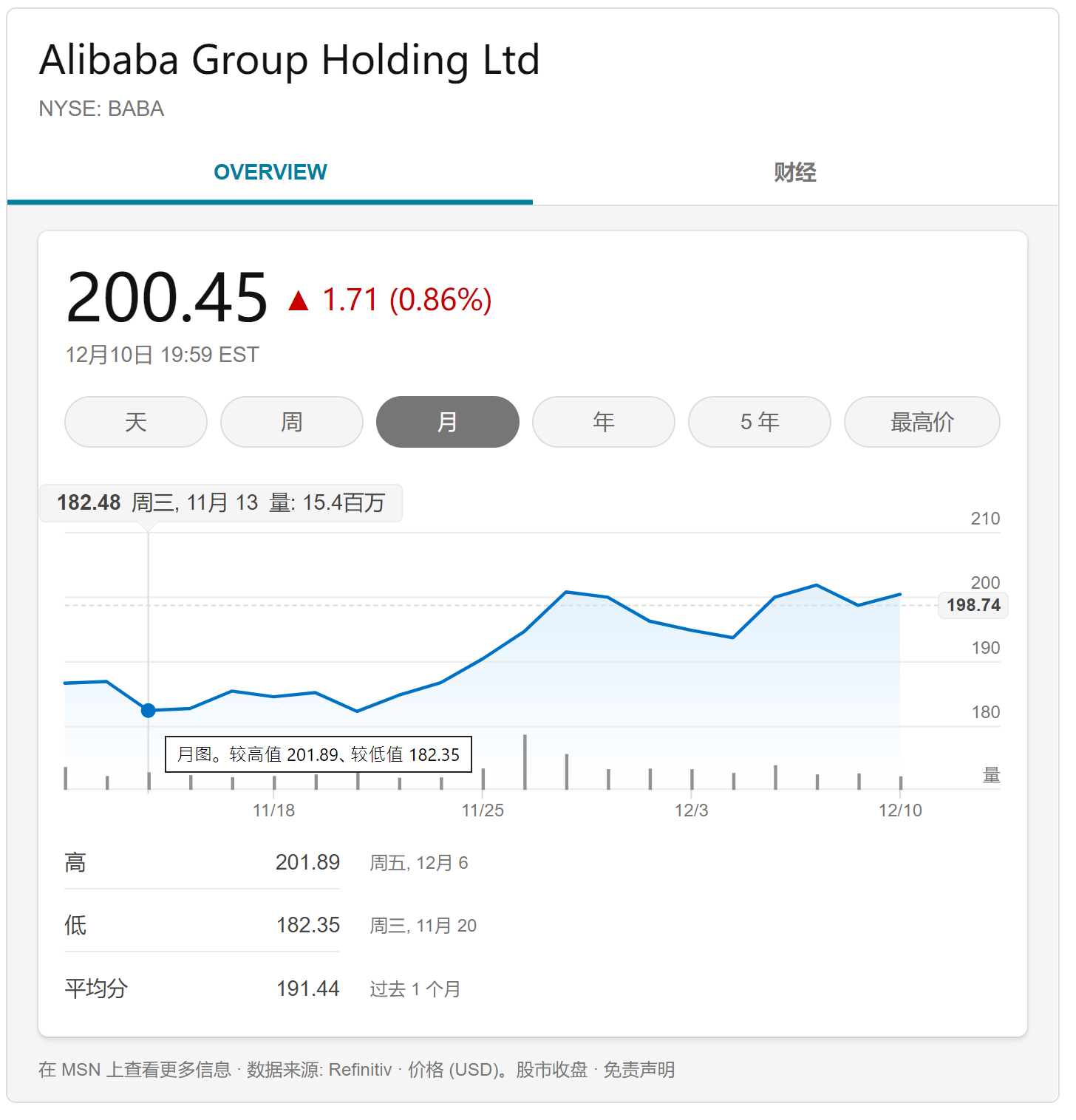
4 一切都是套路
分析并没有到此结束,如果上述的猜测都是真实的话,可能有更多容易忽略的信息值得思考:
- 如果“云舒”所述属实,需要通过临时的增加、减少投放来控制交易额,阿里内部已经有一套非常完备的实时数据流处理体系,能够在最短的时间内展现出当前业务的状况;
- 在此基础上,运营团队有着高效的应对计划,能够针对业绩的缺口进行及时干预,一旦达成目标后立即停止,拥有可怕的实时操控大盘的能力;
- 对于业绩操控的营销手段应该是有过详细的分析和规划的,能够在投放时就掌握预期的反应率情况,即在哪个产品针对哪个客群,给予什么样的优惠政策,可以达到多少反应率、提升多少销售额;在如此庞大的商户和客户规模下,几乎拥有精细到个体的精准营销能力;
具体怎么控制呢?
打个比方说就是叭店里价格200的商品标价2000,限定2000份,在某一时间段发出,然后通过羊毛群群主,通知给普通消费者,让消费者买下,并在确认收货以后全额返还。
这就是免单
我认为大家额度知道叭?
我同学为双十一贡献快一万,其中9千是免单。
包括护肤品,上一季的衣服,茶叶,内衣,全部以福袋方式发放免单
我因为同学薅羊毛不亦乐乎,我就去看了额,一件束腰带800,两瓶精华2000一件我真心考不上的大衣(普通的黑白,袖子看着设计的都有点短)7000。

知乎:秋月白白
很多用户发现双十一的羊毛越来越难薅了,满额、叠加、膨胀,游戏门槛提升,游戏规则复杂,最后买单时发现也就便宜了几块钱,辛辛苦苦这是为了什么?
盖楼活动,又是拉新又是卖VIP,天天PK的新鲜感过去之后,才发现满满的都是套路,最后就是阿里的指标好看了,KPI完成了,员工的奖金才有了着落。
“让世界没有难做的生意”,可在双十一想凑个单,太难了,用户们感觉被耍了。
还有比被耍更令人厌恶的事情呢。
例如:特朗普的竞选团队雇佣Cambridge Analytica公司利用脸书的数据来制造有利于特朗普精选的材料,原理就是基于个人行为的心理学侧写(OCEAN)技术,用大家熟悉的话来说就是“用户画像”,CA分析了民众的政治倾向和参政意愿,对不同偏好的受众投放不同的广告邮件或展示不同的网页信息,曾在帮助特朗普前将另一位之后退出的候选人Ted Cruz的支持率从5%提升到35%。
详见《Cambridge Analytica 是一家怎样的公司?》
双十一的统计数据还是小问题,要警惕的是阿里这类互联网寡头掌握了海量用户的个人信息(其中不乏隐私和敏感信息),是不是会将其用于违反法律和道德的目的。我们没有明确的证据,但是面对这座金山,鲜有能够坐怀不乱的商业公司。
5 数据的反噬
“双十一”是一个人为制造的营销节目,目的是通过优惠返利提升平台的交易量。若由平台承担营销成本,则买家和商户都是受益方,平台获得了流量、口碑、信用和用户体验,是一个多方受益的结果。当平台做大后,当然希望能够压缩营销成本,于是要求商户提供优惠,以降低平台的补贴,于是全平台通用的优惠规则逐渐被商户专享的优惠取代。其好处不仅大大降低了平台的补贴费用,将营销的权利下放给商户,可以由商户根据自身的实力来决定优惠的力度,这对于有一定规模的商户肯定是更好的方案,但是却增加了商户间的竞争,促进了内卷。如果商户一致抵制的话,平台就无法完成双十一的销售额KPI,因此肯定会以各种软硬要求将指标摊派到每个商户,实际上促成和助长了刷单、虚假商品、先涨价再优惠的各种不良行为,甚至滋生了各种灰色、黑色产业链。
过分鼓吹双十一销售额与中国零售经济间的表征关系,无形中被强劲的GDP给绑架了,使其成为一个不得不完成的“政治”任务。
“必然的成功导致必然的造假。”
全国政协委员、科技部部长万钢等就“科技创新”问题接受中外记者采访提问时表示,硬逼着每个科技项目都成功必然导致造假现象。
销售额是用来反应业务开展情况的指标之一,不应当被当作任务终极目标来完成。虽然我们在制定计划和目标时,都会要求量化指标,但是不管是管理者还是执行者,都应当始终关注方式方法,防止执行过程中歪曲理解,恶意追求指标完成,而忽视了合规、合法、合理。目前的大数据和分析技术确实可以在某种程度上帮助我们发现业务上的问题、优化和改进我们的执行策略,也能够预警潜在的问题,但技术是无辜的,要慎重使用,避免被数据反噬。
双十一的成绩能够刚刚完成计划,而没有出现较大的超额完成,除了体现前面所述的强大的营销控制力,也反映出大家都不愿意超额完成任务,或许是因为成本过高,或许是因为会对次年的KPI任务造成更大的压力。事实上,双十一活动已经越来越表现出这样的结果:积压用户一个月的消费意愿,统一在一天内释放,很多营销优惠模式反而会造成一些冲动消费、过度消费和无效消费,这种非正常交易占比多少,我相信阿里内部会有统计分析,当达到一定比例时,整个业务数据就会变成美股那样的泡沫,就看怎么戳破了。金灿荣教授认为“质疑数据造假”是为了打击阿里赴港上市,这有点冷战思维了,只是从目前披露出来的种种负面新闻,逐渐显示淘宝的“双十一”造神运动已经忘记了“初心”,被数据绑架甚至反噬了。
数据无法自我循环,必须依附于某个产品、某个客户或某个流程。数据分析和数据化运营是互联网企业的力气,能够雪中送炭、锦上添花,但是其使用存在局限和天花板。例如:产品创新和模式创新无法通过数据获得,这些必须依赖于人的洞见与创意;借助于A/B测试的决策优化有可能无法反馈长期用户的偏好;以及博弈性场景也无法用数据来做决策。
理性希望,明年双十一的销售额不会再满足这个预测模型,而是主动压低预期并和经济发展解绑。更进一步,应当然后整顿虚假交易、假冒伪劣、灰黑产业链等平台的顽症,使竞价排名的算法公开公平透平,营销活动能够真正回馈消费者和商户,才是正道和“初心”。
Don’t underestimate the power of the dark side. –Lord Vader
