4 Building Good Training Sets – Data Preprocessing
数据的质量和有效信息含量直接决定了机器学习算法能够学得多好。因此在建模前绝对应当对数据进行细查和预处理。本章节将介绍构建模型前必须要具备的数据预处理技术。
- 清除或插补缺失值
- 将分类数据塑形成模型可用的形式
- 为模型构建选择相关的特征变量
Dealing with missing data
我们通常将缺失值视为空格或者NaN。不幸的是,很多计算工具无法处理这类缺失值或者会产生无法预测的结果,因此在进一步分析前需要预先处理这类缺失值。讨论这些方法前我们先来创建一个简单的样例数据,这是一个CSV(comma-separated values)文件。1
2
3
4
5
6
7
8
9import pandas as pd
from io import StringIO
csv_data = '''A,B,C,D
1.0,2.0,3.,4.0
5.0,6.0,,8.0
0.0,11.0,12.0,'''
csv_data = unicode(csv_data)
df = pd.read_csv(StringIO(csv_data))
df
Output:1
2
3
4A B C D
0 1 2 3 4
1 5 6 NaN 8
2 0 11 12 NaN
从输出结果看到我们从CSV格式的数据读入到DataFrame对象后,缺失值被替换为NaN。如果使用Python3,则无需使用unicode函数。对于更大的DataFrame,可以使用insnull方法查看每个单元是否含有数值类型的值,然后用sum方法统计缺失的数量。1
df.isnull().sum()
Output:1
2
3
4
5A 0
B 0
C 1
D 1
dtype: int64
scikit-learn是基于NumPy开发的,有时候用DataFrame处理数据更加便利,因此我们可以通过DataFrame的
values方法获取NumPy数组类型的的数据,并将它喂给scikit-learn的算法。
Eliminating samples or features with missing values
最简单的缺失处理方法是扔掉对应的特征(列)或样本(行)。列和行可以方便地通过dropna方法剔除掉。1
2df.dropna()
df.dropna(axis=1)
Output:1
2
3
4
5
6
7 A B C D
0 1 2 3 4
A B
0 1 2
1 5 6
2 0 11
dropna方法还有一些额外的参数可以实现更加灵活的剔除逻辑。1
2
3
4
5
6
7
8
df.dropna(how='all')
df.dropna(thresh=4)
df.dropna(subset=['C'])
剔除缺失数据简单,但是可能会丢失过多的样本或者太多特征变量,损失对分类算法来说有用的信息。
Imputing missing values
通过其他样本的数据来对缺失值应用各种插补技术,是另外一种处理方式。一个最常用的方式是使用均值插补,scikit-learn的Imputer类可以方便地实现这类工作。1
2
3
4
5from sklearn.preprocessing import Imputer
imr = Imputer(missing_values='NaN', strategy='mean', axis=0)
imr = imr.fit(df)
imputed_data = imr.transform(df.values)
imputed_data
Output:1
2
3array([[ 1. , 2. , 3. , 4. ],
[ 5. , 6. , 7.5, 8. ],
[ 0. , 11. , 12. , 6. ]])
该例子中将缺失值NaN替换为每列的平均值,如果将参数axis=0改为axis=1,将替换为行的平均值。strategy参数其他选项还有median和most_frequent,表示中值和最常出现的值。
Understanding the scikit-learn estimator APIImputer类在scikit-learn中属于transformer类,主要用来对数据进行各种变形,通常包含两个重要的方法fit和transform。fit方法用来在训练集上学习参数,然后通过transform方法和参数对训练数据集进行转换。被转换的数据集必须与学习的数据集具有相同的特征变量数,下图展现了学习参数并应用于新数据集的转化过程。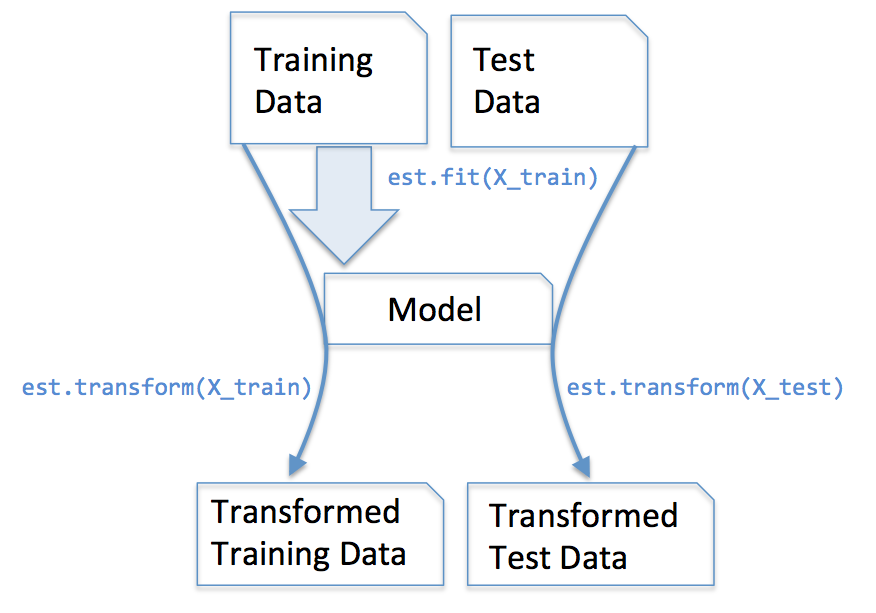
Handling categorical data
至此,我们处理的都是数值类型特征,但在真实数据世界中存在各种分类(categorical)特征数据。分类数据可以分为有序的(ordinal)和无序的(nominal),有序的特征例如T恤衫的尺寸,因为根据定义XL大于L大于M。无序的特征比如T恤衫的颜色,颜色之间的大小排序没有现实意义。
同样我们先来创建一个样例数据集。1
2
3
4
5
6
7
8import pandas as pd
df = pd.DataFrame([
['green', 'M', 10.1, 'class1'],
['red', 'L', 13.5, 'class2'],
['blue', 'XL', 15.3, 'class1']
])
df.columns=['color', 'size', 'price', 'classlabel']
df
Output:1
2
3
4 color size price classlabel
0 green M 10.1 class1
1 red L 13.5 class2
2 blue XL 15.3 class1
该数据中包含一个无序分类特征(颜色),一个有序分类特征(尺寸),一个数值特征(价格),和一个分类标识。本书中讨论的分类算法都无视分类标识中的大小和优先关系。
Mapping ordinal features
我们必须手工定义有序分类特征到整形的映射逻辑关系,假设我们知道特征之间的区别关系,如:XL=L+1=M+21
2
3
4
5size_mapping = {'XL': 3,
'L': 2,
'M': 1}
df['size'] = df['size'].map(size_mapping)
df
Output:1
2
3
4 color size price classlabel
0 green 1 10.1 class1
1 red 2 13.5 class2
2 blue 3 15.3 class1
如果需要将整型转会原始的字符串,可以定义逆映射inv_size_mapping = {v:k for k, v in size_mapping.items()},然后同样适用map方法做一次转换。
Encoding class labels
许多机器学习库都要求分类标识必须使用整型数值,我们可以使用类似于对有序分类特征映射的方法对分类标签进行转换,由于分类标识之间没有优先关系,所以具体数值大小无关紧要,我们可以简单从0开始枚举。1
2
3
4
5import numpy as np
class_mapping = {label:idx for idx, label in enumerate(np.unique(df['classlabel']))}
class_mapping
df['classlabel'] = df['classlabel'].map(class_mapping)
df
Output:1
2
3
4
5
6{'class1': 0, 'class2': 1}
color size price classlabel
0 green 1 10.1 0
1 red 2 13.5 1
2 blue 3 15.3 0
scikit-learn直接实现了一个更方便的LabelEncoder类可以直接实现上述功能。1
2
3
4
5
6inv_class_mapping = {v: k for k, v in class_mapping.items()}
df['classlabel'] = df['classlabel'].map(inv_class_mapping)
from sklearn.preprocessing import LabelEncoder
class_le = LabelEncoder()
y = class_le.fit_transform(df['classlabel'].values)
y
Output:1
array([0, 1, 0])
fit_transform是调用fit和transform的快捷方式,另外还可以直接使用inverse_transform进行逆向转换。1
class_le.inverse_transform(y)
Performing ont-hot encoding on nominal features
可以使用同样的技术对无序分类特征转换成整型,例如:blue -> 0, green -> 1, red -> 2,机器学习算法会假设绿色大于蓝色,红色大于绿色,尽管这个假设并不正确,但是仍然可以得出一些有用的结果(当然不是最优的)。
一个常用的解决是独热编码(one-hot encoding),通过给变量的每一个可能取值都创建一个独立的哑变量(dummy feature)。本例中,可以将颜色特征转换成三个新的变量:blue, green, red,每个变量都通过二元标识来表示对应的颜色取值情况,比如蓝色样本的变量取值为:blue=1, green=0, red=0。scikit-learn.preprocessing模块中的OneHotEncoder实现了该类转换功能.1
2
3
4
5
6X = df[['color', 'size', 'price']].values
color_le = LabelEncoder()
X[:, 0] = color_le.fit_transform(X[:, 0])
from sklearn.preprocessing import OneHotEncoder
ohe = OneHotEncoder(categorical_features=[0])
ohe.fit_transform(X).toarray()
Output:1
2
3array([[ 0. , 1. , 0. , 1. , 10.1],
[ 0. , 0. , 1. , 2. , 13.5],
[ 1. , 0. , 0. , 3. , 15.3]])
DataFrame甚至有一个更加简单的get_dummies方法可以直接将字符类型变量转换成哑变量。1
pd.get_dummies(df[['price', 'color', 'size']])
Output:1
2
3
4 price size color_blue color_green color_red
0 10.1 1 0.0 1.0 0.0
1 13.5 2 0.0 0.0 1.0
2 15.3 3 1.0 0.0 0.0
Partioning a dataset in training and test sets
第一章和第三章都介绍过将建模数据切分为训练集和测试集的概念,本节我们将引入一个新的数据集,通过数据预处理学习几种特征选择的降维技术。
新数据是由UCI提供的葡萄酒数据,其包含了178个酒品样本和13个描述化学属性的特征变量,通过pandas我们可以直接从互联网都如该数据。1
2
3
4
5
6
7df_wine = pd.read_csv('https://archive.ics.uci.edu/ml/machine-learning-databases/wine/wine.data', header=None)
df_wine.columns = ['Class label', 'Alcohol', 'Malic acid', 'Ash',
'Alcalinity of ash', 'Magnesium', 'Total phenols', 'Flavanoids',
'Nonflavanoid phenols', 'Proanthocyanins', 'Color intensity', 'Hue',
'OD280/OD315 of diluted wines', 'Proline']
print('Class labels', np.unique(df_wine['Class label']))
df_wine.head()
Output:
1 | ('Class labels', array([1, 2, 3], dtype=int64)) |
样本包含3个分类,1、2和3,对应意大利不同区域种植的三种不同的葡萄。
通过cross_validation模块的train_test_split方法可以将数据随机分到测试集和训练集。
1 | from sklearn.cross_validation import train_test_split |
Bringing features onto the same scale
特征归一化(feature scaling)是预处理前容易被忽略的重要步骤,除了决策树和随机森林等少数几类算法,将特征变量映射到统一尺度下有助于大多数机器学习算法和调优,通常来说主要有两种方法:归一化(normalization)和标准化(standardization)。归一化指将特征重新映射到[0, 1]的范围,这是一种最大最小归一化的特殊情况(min-max scaling)。每个样本的特征值xi可以按照下述公式得到新值:x’ = (x - min(x))/(max(x)-min(x))。scikit-learn中可以直接使用MinMaxScaler实现。
1 | from sklearn.preprocessing import MinMaxScaler |
实际中标准化比归一化更加常用,因为许多线性模型(如逻辑回归和SBM)的权重初始值会设置为0或者接近0的小随机数,变量经过标准化后形成正态分布,均值为0,标准差为1,标准化还能够保留离群值(outliers)信息,但又不会影响算法。标准化常用的方法如下: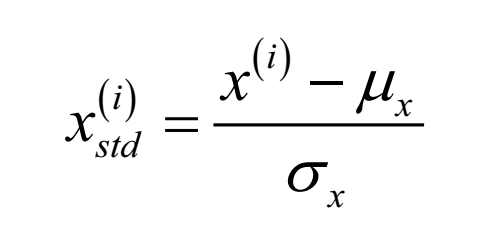
其中µ 是样本均值,σ 是标准差。
下表展示了同一个变量经过归一化和标准化之后的结果:
1 | input standardized normalized |
scikit-learn同样实现了标准化的类:
1 | from sklearn.preprocessing import StandardScaler |
注意StandardScaler只训练一次,然后用来后续的所有测试和验证数据集。
更加细节内容可以参照:http://www.zhaokv.com/2016/01/normalization-and-standardization.html
Selecting meaningful features
如果一个模型在训练集上的表现明显优于测试集,则意味着过拟合,也称为高方差(variance),通常是模型过于复杂造成。解决方案如下:
收集更多训练数据
进入针对复杂程度的惩罚系数,例如之前介绍的正则化方法
选择一个参数更少的简单模型
对建模数据进行降维
收集更多数据通常受到实际限制,本节将介绍正则化和变量选择降维技术来降低过拟合。
Sparse solutions with L1 regularization
第三章中介绍L2 regularization是一种降低模型复杂程度的方法,L1 regularization则是另一种。对于scikit-learn中支持L1 regularization的模型,可以简单的添加penalty参数并设置为`’l1’。
1 | from sklearn.linear_model import LogisticRegression |
Output:
1 | Training accuracy: 0.983870967742 |
结果显示模型在训练集上和测试机上都没有出现过拟合。当我们查看lr.intercept_属性,可以看到返回一个有三个值的数组:
1 | array([-0.38381622, -0.15806481, -0.70048192]) |
由于我们用LogisticRegression在一个多分类数据上建模,算法默认会使用One-vs-Rest方法,第一个参数对应的是分类1对分类2和分类3,第二个参数是分类2对分类1和分类3,第三个参数是分类3对分类1和分类2。lr.coef_获取的权重数组有三条记录,每条对应一个分类的参数权重。这里每条记录都有13个权重参数对应了13个特征变量。
1 | array([[ 0.28007103, 0. , 0. , -0.02793263, 0. , |
可以看到参数矩阵是稀疏的,意味经过L1正则化完成了特征筛选,使得训练的模型可以不受数据中不相关特征的影响。最后,通过调整正则化力度,观察不同变量的权重系数变化情况。
1 | import matplotlib.pyplot as plt |
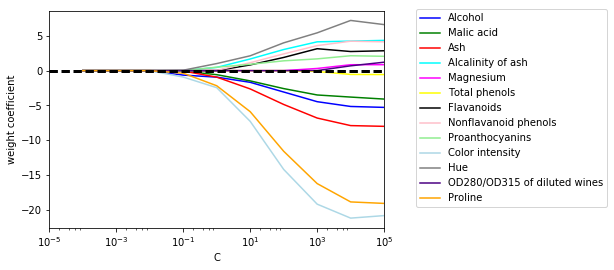
上图展示了L1正则化对所有参数的作用,当正则化参数很强(C<0.1)时,所有特征的权重都会趋于0。
Sequential feature selection algorithms
另一个降低模型复杂度避免过拟合的方法是通过特征筛选进行降维(dimensionality reduction),这对于非正则化(unregularized)模型尤为有用。降维主要有两类技术:特征选择(feature selection)和特征抽取(feature extraction)。前者是从原始变量中选择部分特征,而后者是基于原变量构建一个特征子空间。本章我们将探索特征筛选算法,下章节将介绍特征抽取技术。
序列特征选择(Sequential feature selection)是一类贪婪搜索算法,用于将初始d维特征子集压缩到k维特征子集上。算法的原理是自动选择一个特征子集,通过删除不相关的特征或者噪音数据使得模型能够提升计算效率或降低泛化误差(generalization error)。一个经典的序列特征选择算法是序列后向选择(Sequential Backward Selection,SBS)。SBS从特征全集开始,每次从中剔除一个特征,直到特征数量达到希望值。为了判断每次剔除哪个变量,需要定义一个评价函数J,J可以简单定义为剔除特定变量前后之间的性能差异,这样只要保证每次剔除的变量的评价函数J最小即可。SBS算法没有在scikit-learn中实现,但是因为非常简单,我们可以自行完成:
1 | from sklearn.base import clone |
我们实现的方法中,k_features参数定义了需要的特征数量,scoreing参数默认使用scikit-learn的accuracy_score来评估特征子集上的模型分类效果。在while循环中的fit方法,itertools.combination方法不断精简生成新的特征子集并评价模型表现,知道特征数量满足我们的制定要求。每一次循环中表现最好的特征子集的准确度存放于self.scores_列表中,最终特征变量的下标会存储在self.indices_中,可以方便的用transform方法生成选中特征的数据集。注意在fit方法中,我们简单的将不在最佳表现特征子集中的列去除,而没有显示计算各特征组合的差异。
现在我们可以将SBS算法应用于KNN分类算法中实践一下:
1 | from sklearn.neighbors import KNeighborsClassifier |
我们在SBS实现中已经在fit方法中将输入数据集拆分为训练和测试集,所以可以直接输入X_train训练集。这个步骤必不可少,可以避免我们原始的测试数据成为训练数据的一部分。
1 | k_feat = [len(k) for k in sbs.subsets_] |
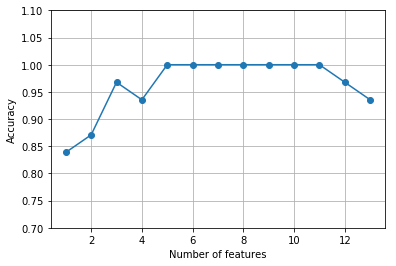
从上图结果可以看到,当特征数量下降时,KNN分类器的准确度获得提升。为了满足我们的好奇心,可以查看准确度达到100%时的5个特征是什么,通过获取sbs.subsets_的第9个(也就是特征数为5时)的特征变量名:
1 | k5 = list(sbs.subsets_[8]) |
Output:
1 | Index(['Alcohol', 'Malic acid', 'Alcalinity of ash', 'Hue', 'Proline'], dtype='object') |
下一步,验证一下KNN分类器在原始测试集上的表现性能:
1 | knn.fit(X_train_std, y_train) |
Output:
1 | Training accuracy: 0.983870967742 |
首先我们使用完整特征集训练的模型,在训练集上精准度约为98.4%,在测试集上准确度誉为94.4%,显示模型有一定程度的过拟合。现在我们使用选择的5个特征来重新训练:
1 | knn.fit(X_train_std[:, k5], y_train) |
Output:
1 | Training accuracy: 0.959677419355 |
使用比原来少一半的特征,KNN模型在测试数据集上的精准度提升了2个百分点,并且与训练集上的精准度差异明显小,显著降低模型的过拟合度。
Feature selection algorithms in scikit-learn
Assessing feature importance with random forests
除了用SBS算法和逻辑回归,还可以利用随机森林来选择相关特征。通过随机森林,在无需关注数据是否线性可分的情况下,直接通过所有决策树计算出的平均杂质度减少情况来评估特征的重要程度。scikit-learn中的随机森林算法已经手机了特征重要度,我们可以在训练后方便地通过feature_importances_属性来访问。下面的代码中,我们现在Wine数据上训练10000棵树的随机森林,并对13个特征的重要性排名。基于树的模型无需标准化和规范化。
1 | from sklearn.ensemble import RandomForestClassifier |
Output:
1 | 1) Alcohol 0.182483 |
所有特征的重要度已经经过规范化,它们的总和等于1.0。通过10000棵决策树训练的结论是alcohol是区分酒对重要的特征变量,且排名靠前的3个特征也在之前SBS算法选择的5个特征中。不过就可解释性而言,随机森林有个问题需要注意,如果两个和多个特征高度相关,一个特征会获得很高的排名而其它相关的特征会被忽视。如果我们仅仅关心模型的预测能力而不用解释变量的重要性则不必过分关注这个问题。
最后,scikit-learn中的随机森林分类器同样实现了transform方法,可以基于用户指定的阈值选择特征变量,例如我们可以设定阈值为0.15,将Wine数据集的变量限定在最重要的三个。
1 | X_selected = forest.transform(X_train, threshold=0.15) |
Output:
1 | (124, 3) |