Python Machine Learning
Sebastian Raschka是密歇根州立大学的博士生,擅长Python和机器学习,是GitHub广受欢迎的数据科学家之一。
1 Giving Computers the Ability to learn from Data
Building intelligent machines to transform data into knowledge
The three defirent types of machine learning
机器学习的三种类型:无监督学习、有监督学习、增强学习
Making predictions about the future with supervised learning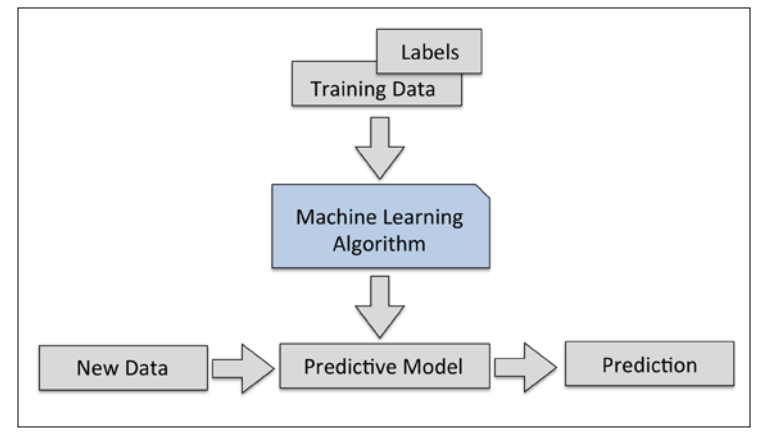
Classification for predicting class labels
分类是有监督学习的一类,包括二元分类(如是别垃圾邮件)、多元分类(如手写识别)
Regression for predicting continuous outcomes
回归是分析一组预测因子和连续性结论之间的关系,用来预测连续性结果,例如使用学习时间和SAT成绩关系
Solving interactive problems with reinforcement learning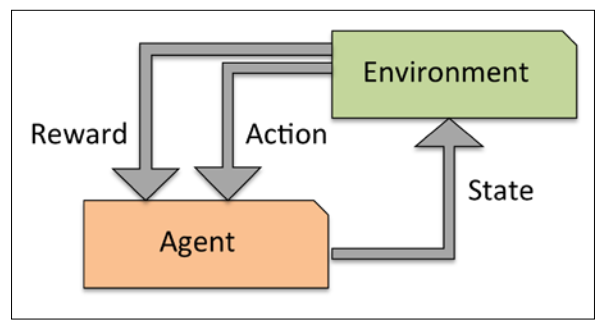
增强学习的目的是构建一个通过与环境交互不断提升表现的系统。因为基于reward signal,可以认为与有监督学习类似。但reward signal并不是表示真假或数值,而是有reward函数对交互行为产生的效益的评价,典型的增强学习是下棋引擎,交互行为就是下子,reward就是最终的输赢。
Discovering hidden structures with unsupervised learning
有监督学习中,建模前必须有正确的结果数据,增强学习也必须预定义reward函数。而无监督学习是试图探索数据中的潜在信息和结构模式。
Finding subgroups with clustering
聚类技术是将数据重组成有意义的簇,使得在某维度上簇内相似度最高、簇间相似度最低。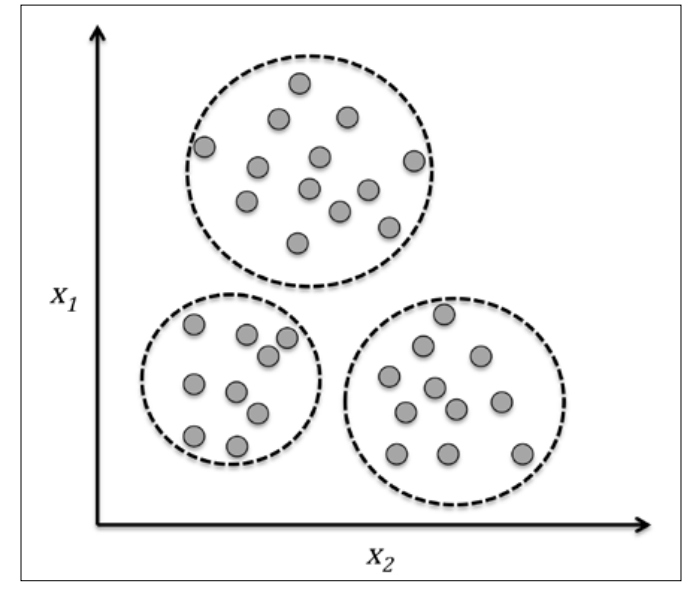
Dimensionality reduction for data compression
降维是另一种无监督学习,是一种常用的特征预处理方法,去除噪音数据,压缩数据维度空间,但仍保留有效的信息量。
A roadmap for building machine learning systems
下图展示了一个典型的预测模型构建工作流程: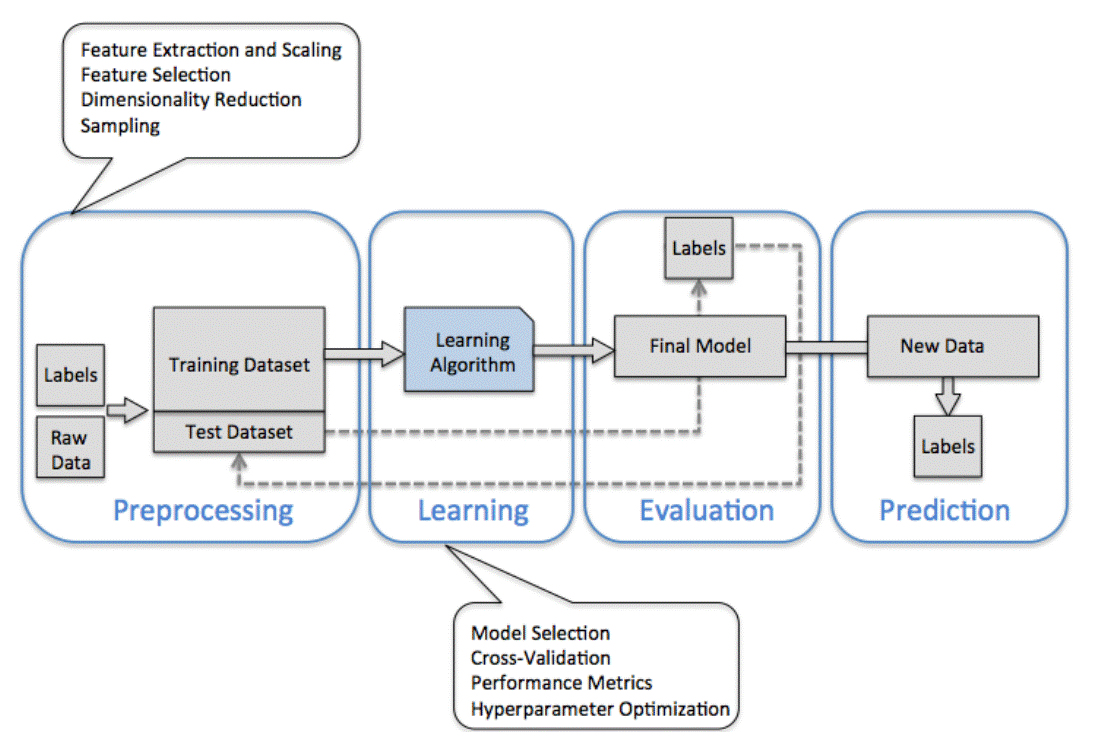
Preprocessing – getting data into shape
数据预处理是最关键的步骤之一
Training and selecting a predictive model
每个分类算法都有其内在的偏向,在任务未知时没有哪个信号分类模型更加优秀。在比较不同模型效果是,首先需要定义和量指标,即分类的准确率。
由于我们无法知道最终预测数据是怎样的,所以引入了各种交叉检验技术将建模数据分为训练和检验部分来评估模型效果。最后我们还要使用超参数(hyperparameter)优化技术来对模型调优。
Evaluating models and predicting unseen data instances
一旦模型训练完成,我们能够用测试数据验证效果,如果模型效果满意,就能够用来预测未来的新数据。