8 绘图和可视化
绘图是数据分析工作中最重要的任务之一,通过可视化的方式能够让我们快速进行探索过程,找出异常值、进行数据转换、获取模型的idea。Python有许多可视化工具,这里主要介绍matplotlib。
8.1 matplotlib API入门
准备工作:
1 | %matplotlib inline # 在IPython中内嵌显示matplot图表,也可以在IPython启动时增加--pmatplotlib=inline参数实现 |
Figure和Subplot
matplotlib的图像都位于Figure对象中,用plt.figure可以创建一个新的Figure对象,通过plt.gcf()获得当前Figure对象的引用,不能通过空Figure绘图,必须用add_subplot创建或多个subplot才行。
1 | fig = plt.figure() |
上面的代码创建一个空2x2的Figure,并依次创建3个subplot。

如果这是使用绘图指令,matplotlib会在最后一个用过的subplot上绘制,如果执行下列命令会在第二行第一个图中绘制图表。
1 | from numpy.random import randn |
k--是一个线性选项,表示绘制黑色虚线图。add_subplot返回的是AxesSubplot对象,直接调用他们的实例方法就可以在其中直接画图。
1 | _ = ax1.hist(randn(100), bins=20, color='k', alpha=0.3) |
由于根据特定布局创建Figure和Subplot非常常用,因此出现了跟方便的方法plt.subplots,可以创建一个新的Figure,并返回一个含有已创建subplot对象NumPy数组。
1 | fig, axes = plt.subplots(2, 3) |
Output:
1 | array([[<matplotlib.axes.AxesSubplot object at 0x109761290>, |
调整subplot周围的间距
默认情况下,subplot外围预留一定的编剧,并在subplot之间留下一定的间距。间距跟图像的高度和宽度有关,因此会根据图像的大小自动调整,利用Figure的subplots_adjust方法修改间距,此外这是一个定基函数。
1 | subplots_adjuct(left=None, buttom=None, right=None, top=None, wspace=None, hspace=None) |
其中wspace和hspace用于控制宽度和高度的百分比,可以用作subplot之间的间距。如果将这两个参数设置为0,会发现两个subplot的轴标签产生了重叠。matplotlib不会检查标签是否重叠,所以这种情况需要自行设定刻度的位置和刻度的标签。
1 | fig, axes = plt.subplots(2, 2, sharex=True, sharey=True) |
颜色、标记和线型
plot方法除了接收一组X和Y的坐标,还可以接受一个表示颜色和现行的字符串缩写,例如之间的"k--"表示黑色虚线,更为明确的方式如下:
1 | ax.plot(x, y, linestyle='--', color='g', marker='o') |
分别表示线型、颜色和数据点的标记。常用颜色都有一个缩写,也可以通过RGB值的形式自定义任意颜色(’#CECECE’)。
在线型图中,非实际数据点默认是按线性方式插值的,但可以通过drwastyle选项修改。
1 | data = randn(30).cumsum() |
刻度、标签和图例
设置标题、轴标签、刻度以及刻度标签
修改X轴的刻度可以使用set_xticks和set_xticklabels方法,前者表明讲刻度放在数据范围中的哪些位置,默认情况下,这些位置就是刻度标签。但是通过后一个方法可以将任何其他的值用作标签。
1 | fig = plt.figure(); ax = fig.add_subplot(1, 1, 1) |
添加图例
最简单的实在添加subplot时传入label参数,在此之后,可以调用legeng()方法来创建图例,loc参数告诉matplotlib将图里放在那里,一般来说best是一个不错的选择,它会选择最不碍事的位置。
1 | ax.plot(randn(1000).cumsum(), 'k--', label='onw') |
注解以及在Subplot上绘图
除标准图标对象以外,matplotlib还支持绘制自定义的注解文本、标注箭头等图像,可以通过text、arrow和annotate等函数进行添加。
1 | ax.text(x, y, 'Hello word!', family='monospace', fontsize=10) |
下面是一个示例,更多功能可以访问matplotlib在线示例库。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23import pandas as pd
from datetime import datetime
fig = plt.figure()
ax = fig.add_subplot(1, 1, 1)
data = pd.read_csv('../../../pydata-book-master/ch08/spx.csv', index_col=0, parse_dates=True)
spx = data['SPX']
spx.plot(ax=ax, style='k-')
crisis_data = [
(datetime(2007, 10, 11), 'Peak of bull market'),
(datetime(2008, 3, 12), 'Bear Stearns Fails'),
(datetime(2008, 9, 15), 'Lehman Bankruptcy')
]
for date, label in crisis_data:
ax.annotate(label, xy=(date, spx.asof(date) + 50),
xytext=(date, spx.asof(date) + 200),
arrowprops=dict(facecolor='black'),
horizontalalignment='left', verticalalignment='top')
ax.set_xlim(['1/1/2007', '1/1/2011'])
ax.set_ylim([600, 1800])
ax.set_title('Important dates in 2008-2009 financial crisis')
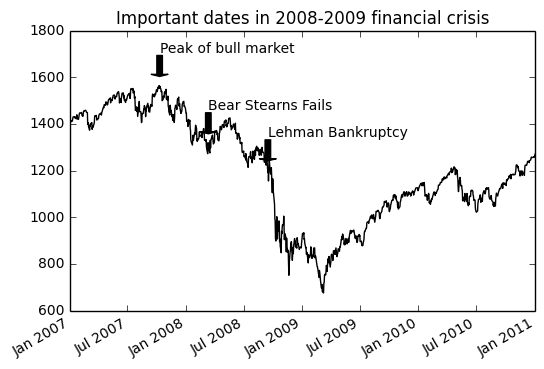
将图表保存到文件
利用plt.savefig可以讲图表保存到文件,常用的选项dpi表示每英寸像素数和bbox_inches剪除当前图表周围空白部分。
1 | plg.savefig('figpath.svg', dpi=400, bbox_inches='tight') |
savefig也可以写入任何文件类型对象,比如StringIO。这对于在Web上提供动态生成的图片很实用。
1 | from io StringIO |
matplotlib配置
matplotlib自带一些配色方案,以及为生成出版质量图片的默认配置信息,一种才做配置信息的方式是利用rc方法。rc方法的第一个参数是希望定义的对象,如'figure'、'axes'、'xtick'、'ytick'、'grid'、'legend'等,其后可以跟上一系列关键字,简单的方法是将选项写成一个字典。
1 | font_options = {'family': 'monospace', |
要了解全部的自定义,请查阅matplotlib的配置文件matplotlibrc(位于matplotlib/mpl-data目录中)。
8.2 pandas中的绘图函数
matplotlib实际上还是比较低级的,在pandas中提供了许多直接利用DataFrame对象数据组织特点来创建标准图表的高级绘图方法。
线型图
Series和DataFrame都有一个用于生成各类图表的plot方法,默认情况下生成的是线型图。
1 | s = Series(np.random.randn(10).cumsum(), index=np.arange(0, 100, 10)) |
该Series对象的索引会被用以绘制X轴(可以通过use_index=False禁用),X轴的刻度和界限通过xticks和xlim选项调节,Y轴类似。pandas的大部分绘图方法都有一个可选的ax参数,用来在网格布局中灵活处理subplot的位置。
DataFrame的plot方法会在一个subplot中为各列绘制一条曲线,并自动创建图例。
1 | df = DataFrame(np.random.randn(10, 4).cumsum(0), |
Series.plot方法的参数:
- label: 用于图例的标签
- ax:指定在其上进行绘制的subplot对象
- style:床给matplotlib的风格字符串(例如
'ko--') - alpha:图表的不透明度(0~1之间)
- kind:可以是’line’、’bar’、’barh’、’kde’
- logy:在Y轴上使用对数标尺
- use_index:是否将对象的索引用作刻度标签
- rot:旋转刻度标签(0到360)
- xticks:用作X轴刻度的值
- yticks:用作Y轴刻度的值
- xlim:X轴的界限(例如[0, 10])
- ylim:Y轴的界限
- grid:显示轴网格线(默认关闭)
DataFrame专用的plot参数:
- subplots:将各个DataFrame列绘制到单独的subplot中
- sharex:如果subplots=True,则公用同一个X轴,包括刻度和界限
- sharey:如果subplots=True,则公用同一个Y轴
- figsize:表示图像大小的元组
- title:表示图像标题的字符串
- legend:添加一个subplot图例(默认为True)
- sort_columns:以字母表顺序绘制各列,默认使用当前列顺序
柱状图
在生成线型图的代码中加上kind='bar'(垂直柱状图)或kind='barh'(水平条形图)即可生成柱状图,设置stacked=True即可为DataFrame生成堆积柱状图,配合value_counts就可以生成百分比堆积柱图。
1 | tips = pd.read_csv('../../../pydata-book-master/ch08/tips.csv') |
直方图和密度图
直方图(histogram)是一种可以对值频率进行离散化显示的柱状图。前面的例子中,通过Series的hist方法,可以生成一张“消费占消费总额比例”的直方图。与此相关的是密度图,通过计算“可能会产生观测数据的连续概率分布估计”而产生,调用plot是加上kind='kde'即可生成。
1 | tips['tip_pct'] = tips['tip']/tips['total_bill'] |
散布图
散布图(scatter plot)是观察两个一维数据序列之间关系的有效手段。matplotlib的scatter方法是绘制散布图的主要方法。在探索式数据分析工作中,同时观察一组变量的散布图是很有意义的,这也被称为散布图矩阵(scatter plot matrix),pandas提供了一个从DataFrame创建散布图矩阵的scatter_matrix函数,它还支持在对角线上放置各变量的直方图或密度图。
1 | macro = pd.read_csv('../../../pydata-book-master/ch08/macrodata.csv') |
1 | pd.scatter_matrix(trans_data, diagonal='kde', c='k', alpha=0.3) |
8.3 绘制地图:图形化显示海地地震危机数据
Ushahidi是一家通过短信收集自然灾害和地缘政治事件信息的非盈利软件公司,这里我们利用pandas以及目前学过的工具处理2010年海地地震期间的数据,一边为分析和图形化工作做准备。
首先读入并看看数据的情况。1
2
3data = pd.read_csv('ch08/Haiti.csv')
data
data[['INCIDIENT DATE', 'ATITUDE', 'LONGITUDE']][:10]
Output:1
2
3
4
5
6
7
8
9
10
11 INCIDENT DATE LATITUDE LONGITUDE
0 05/07/2010 17:26 18.233333 -72.533333
1 28/06/2010 23:06 50.226029 5.729886
2 24/06/2010 16:21 22.278381 114.174287
3 20/06/2010 21:59 44.407062 8.933989
4 18/05/2010 16:26 18.571084 -72.334671
5 26/04/2010 13:14 18.593707 -72.310079
6 26/04/2010 14:19 18.482800 -73.638800
7 26/04/2010 14:27 18.415000 -73.195000
8 15/03/2010 10:58 18.517443 -72.236841
9 15/03/2010 11:00 18.547790 -72.410010
每条记录都有一个时间戳和经纬度。
1 | data['CATEGORY'][:6] |
Output:1
2
3
4
5
6
70 1. Urgences | Emergency, 3. Public Health,
1 1. Urgences | Emergency, 2. Urgences logistiqu...
2 2. Urgences logistiques | Vital Lines, 8. Autr...
3 1. Urgences | Emergency,
4 1. Urgences | Emergency,
5 5e. Communication lines down,
Name: CATEGORY, dtype: object
CATEGORY字段存储消息的类型,类型是一组用逗号分隔的代码。仔细观察上面那个数据就会发现有些分类信息缺失。
1 | data.describe() |
Output:1
2
3
4
5
6
7
8
9 Serial LATITUDE LONGITUDE
count 3593.000000 3593.000000 3593.000000
mean 2080.277484 18.611495 -72.322680
std 1171.100360 0.738572 3.650776
min 4.000000 18.041313 -74.452757
25% 1074.000000 18.524070 -72.417500
50% 2163.000000 18.539269 -72.335000
75% 3088.000000 18.561820 -72.293570
max 4052.000000 50.226029 114.174287
地理位置信息明显存在一些异常,清除这些错误和确实信息是比较简单的。分类信息需要进行额外规整化处理,因此需要编写额外的函数来协助拆分和解析信息。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21data = data[(data.LATITUDE > 18) & (data.LATITUDE < 20) &
(data.LONGITUDE > -75) & (data.LONGITUDE < -70) &
data.CATEGORY.notnull()]
def to_cat_list(catstr):
stripped = (x.strip() for x in catstr.split(','))
return [x for x in stripped if x]
def get_all_categories(cat_series):
cat_sets = (set(to_cat_list(x)) for x in cat_series)
return sorted(set.union(*cat_sets))
def get_english(cat):
code, names = cat.split('.')
if '|' in names:
names = names.split('|')[1]
return code, names.strip()
all_cats = get_all_categories(data.CATEGORY)
english_mapping = dict(get_english(x) for x in all_cats)
english_mapping['2a']
Output:1
'Food Shortage'
为了使用方便,对于存在多个取值的分类变量可以通过添加哑变量的方式进行转换。这里无法使用pandas的get_dummies方法,因此需要手动编写遍历函数处理。1
2
3
4
5
6
7def get_code(seq):
return [x.split('.')[0] for x in seq if x]
all_codes = get_code(all_cats)
code_index = pd.Index(np.unique(all_codes))
dummy_frame = DataFrame(np.zeros((len(data), len(code_index))), index=data.index, columns=code_index)
dummy_frame.ix[:, :6]
如果顺利的话这将构建一个包含所有哑变量(列)的全零DataFrame,行索引则和data的索引一样。Output:1
2
3
4
5
6
7
8
9
10 1 1a 1b 1c 1d 2
0 0.0 0.0 0.0 0.0 0.0 0.0
4 0.0 0.0 0.0 0.0 0.0 0.0
5 0.0 0.0 0.0 0.0 0.0 0.0
6 0.0 0.0 0.0 0.0 0.0 0.0
7 0.0 0.0 0.0 0.0 0.0 0.0
8 0.0 0.0 0.0 0.0 0.0 0.0
9 0.0 0.0 0.0 0.0 0.0 0.0
10 0.0 0.0 0.0 0.0 0.0 0.0
... ... ... ... ... ... ...
然后将各行中适当的项设置为1,再与data进行连接。1
2
3
4
5
6for row, cat in zip(data.index, data.CATEGORY):
codes = get_code(to_cat_list(cat))
dummy_frame.ix[row, codes] = 1
data = data.join(dummy_frame.add_prefix('category_'))
data.ix[:, 10:15]
这样data基友了一些新的列来表示消息的分类。Output:1
2
3
4
5
6
7
8
9
10 category_1 category_1a category_1b category_1c category_1d
0 1.0 0.0 0.0 0.0 0.0
4 1.0 0.0 0.0 0.0 0.0
5 0.0 0.0 0.0 0.0 0.0
6 0.0 0.0 0.0 0.0 0.0
7 0.0 0.0 0.0 0.0 0.0
8 0.0 0.0 0.0 0.0 0.0
9 0.0 0.0 0.0 0.0 0.0
10 0.0 1.0 0.0 0.0 0.0
... ... ... ... ... ...
通过matplotlib的一个插件basemap,可以用Python在地图上会这2D地图数据。下面这个函数可以绘制一张简单的黑白海地地图。1
2
3
4
5
6
7
8
9
10
11
12
13from mpl_toolkits.basemap import Basemap
import matplotlib.pyplot as plt
def basic_haiti_map(ax=None, lllat=17.25, urlat=20.25, lllon=-75, urlon=-71):
m = Basemap(ax=ax, projection='stere',
lon_0=(urlon + lllon) / 2,
lat_0=(urlat + lllat) / 2,
llcrnrlat=lllat, urcrnrlat=urlat,
llcrnrlon=lllon, urcrnrlon=urlon,
resolution='f')
m.drawcoastlines()
m.drawstates()
m.drawcountries()
return m