1 Improving Our Features
书接上回,我们刚刚完成了第一个Kaggle竞赛模型的提交,预测准确率是75%左右,排名将近5000。
本回将从以下三个方面来提高:
- 使用更好的机器学习算法
- 优化特征变量
- 结合多种机器学习算法
Let’s do it.
2 Random Forest Introduction
首先我们引入一个新的算法决策树,决策树能够有效应对非线性关系。
举个栗子:1
2
3
4
5Age Sex Survived
5 0 1
30 1 0
70 0 1
20 0 1
Age和Survived没有线性关系,这里可以使用决策树建立Age、Sex和Survived之间的关系: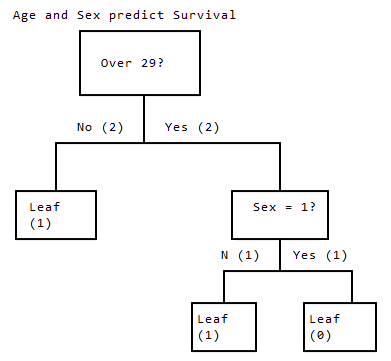
- 首先按照
Age分组,小于等于29岁的进入左侧分枝,大于29岁的进入右侧分支 - 左侧分枝全部存活
- 右侧分枝再根据
Sex进行分组,女性存活,男性未存活
由于决策条件过分依赖于训练数据集的分布情况,其主要缺点是对于训练数据集的过拟合。
由此基础上我们产生了随机森林(Random Forest)算法。在整体样本上随机产生多个训练子集,然后通过对决策点条件随机化,建立上百颗决策树,然后通过对预测结果的平均化,就可以得出一个最小化过拟合的整体预测结果。
3 Implementing A Random Forest
sklearn已经为我们提供了随机森林算法,我们可以直接在训练集上使用并进行交叉检验。1
2
3
4
5
6
7
8
9
10
11
12
13from sklearn.ensemble import RandomForestClassifier
predictors = ["Pclass", "Sex", "Age", "SibSp", "Parch", "Fare", "Embarked"]
# Initialize our algorithm with the default paramters
# n_estimators is the number of trees we want to make
# min_samples_split is the minimum number of rows we need to make a split
# min_samples_leaf is the minimum number of samples we can have at the place where a tree branch ends (the bottom points of the tree)
alg = RandomForestClassifier(random_state=1, n_estimators=10, min_samples_split=2, min_samples_leaf=1)
kf = KFold(n_splits=3, random_state=1).split(titanic)
scores = model_selection.cross_val_score(alg, titanic[predictors], titanic["Survived"], cv=kf)
print(scores.mean())
Output:1
0.785634118967
4 Parameter Tuning
首先也是最简单的提升随机森林算法精准度的方法是增加决策树的数量。训练更多的决策树需要花费更多的时间,但是因为我们最终是使用所有预测的平均值,这也意味着能够大大提升精准度。
我们也可以调整(增加)min_samples_split和min_sambles_leaf变量来降低过拟合,提升模型得分。一个更通用(也就是没有过拟合)的模型,在未知的数据上表现更好,但是在已知的数据上则相反。1
2
3
4alg2 = RandomForestClassifier(random_state=1, n_estimators=50, min_samples_split=4, min_samples_leaf=2)
scores2 = model_selection.cross_val_score(alg2, titanic[predictors], titanic["Survived"], cv=3)
print(scores2, scores2.mean())
Output:1
(array([ 0.8013468 , 0.82154882, 0.83838384]), 0.82042648709315369)
5 Generating New Features
我们还可以衍生新的变量,例如:
- 姓名的长度,可能和乘客的富有程度有关,而富有程度与舱位有关
- 家庭的总人数
SibSp+Parch
pandas的.apply方法可以轻易的生成衍生变量,通过传入一个lambda函数来定义变量上的操作。1
2
3
4
5# Generating a familysize column
titanic["FamilySize"] = titanic["SibSp"] + titanic["Parch"]
# The .apply method generates a new series
titanic["NameLength"] = titanic["Name"].apply(lambda x: len(x))
6 Using The title
通过分析发现姓名中包含有乘客头衔,型如Master.、Mr.、Mrs.等,其中不乏常用的,也有仅1、2个人用的特殊头衔。
我们将利用正则表达式提取出所有的头衔,然后转换成整型,最后生成一个数值型变量Title。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25import re
# A function to get the title from a name.
def get_title(name):
# Use a regular expression to search for a title. Titles always consist of capital and lowercase letters, and end with a period.
title_search = re.search(' ([A-Za-z]+)\.', name)
# If the title exists, extract and return it.
if title_search:
return title_search.group(1)
return ""
# Get all the titles and print how often each one occurs.
titles = titanic["Name"].apply(get_title)
print(pandas.value_counts(titles))
# Map each title to an integer. Some titles are very rare, and are compressed into the same codes as other titles.
title_mapping = {"Mr": 1, "Miss": 2, "Mrs": 3, "Master": 4, "Dr": 5, "Rev": 6, "Major": 7, "Col": 7, "Mlle": 8, "Mme": 8, "Don": 9, "Lady": 10, "Countess": 10, "Jonkheer": 10, "Sir": 9, "Capt": 7, "Ms": 2}
for k,v in title_mapping.items():
titles[titles == k] = v
# Verify that we converted everything.
print(pandas.value_counts(titles))
# Add in the title column.
titanic["Title"] = titles
Output:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29Mr 517
Miss 182
Mrs 125
Master 40
Dr 7
Rev 6
Col 2
Major 2
Mlle 2
Countess 1
Ms 1
Lady 1
Jonkheer 1
Don 1
Mme 1
Capt 1
Sir 1
Name: Name, dtype: int64
1 517
2 183
3 125
4 40
5 7
6 6
7 5
10 3
8 3
9 2
Name: Name, dtype: int64
7 Family Groups
幸存者很可能是依靠家人或者周围的朋友的帮助,因此乘客所属的家庭有可能是一个好变量。这里我们通过乘客的姓氏,加上FamilySize来标识出不同的家庭,然后根据每个乘客所属的家庭赋一个代码。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31import operator
# A dictionary mapping family name to id
family_id_mapping = {}
# A function to get the id given a row
def get_family_id(row):
# Find the last name by splitting on a comma
last_name = row["Name"].split(",")[0]
# Create the family id
family_id = "{0}{1}".format(last_name, row["FamilySize"])
# Look up the id in the mapping
if family_id not in family_id_mapping:
if len(family_id_mapping) == 0:
current_id = 1
else:
# Get the maximum id from the mapping and add one to it if we don't have an id
current_id = (max(family_id_mapping.items(), key=operator.itemgetter(1))[1] + 1)
family_id_mapping[family_id] = current_id
return family_id_mapping[family_id]
# Get the family ids with the apply method
family_ids = titanic.apply(get_family_id, axis=1)
# There are a lot of family ids, so we'll compress all of the families under 3 members into one code.
family_ids[titanic["FamilySize"] < 3] = -1
# Print the count of each unique id.
print(pandas.value_counts(family_ids))
titanic["FamilyId"] = family_ids
Output:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29-1 800
14 8
149 7
63 6
50 6
59 6
17 5
384 4
27 4
25 4
162 4
8 4
84 4
340 4
43 3
269 3
58 3
633 2
167 2
280 2
510 2
90 2
83 1
625 1
376 1
449 1
498 1
588 1
dtype: int64
8 Finding The Best Features
机器学习最重要的工作是变量设计,我们希望能够选用最好的变量。一个方法是单变量特征选择(univariate feature selection),它通过逐个分析那个字段与目标之间的关系强烈。
同样,sklearn内置的函数SelectKBest能够帮我们筛选出最强的特征。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18%pylab inline
import numpy as np
from sklearn.feature_selection import SelectKBest, f_classif
import matplotlib.pyplot as plt
predictors = ["Pclass", "Sex", "Age", "SibSp", "Parch", "Fare", "Embarked", "FamilySize", "Title", "FamilyId"]
# Perform feature selection
selector = SelectKBest(f_classif, k=5)
selector.fit(titanic[predictors], titanic["Survived"])
# Get the raw p-values for each feature, and transform from p-values into scores
scores = -np.log10(selector.pvalues_)
# Plot the scores. See how "Pclass", "Sex", "Title", and "Fare" are the best?
plt.bar(range(len(predictors)), scores)
plt.xticks(range(len(predictors)), predictors, rotation='vertical')
plt.show()
Output: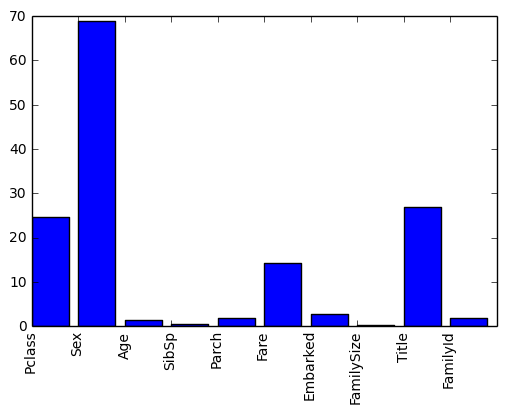
1 | # Pick only the four best features. |
Output:1
(array([ 0.78114478, 0.83838384, 0.83164983]), 0.81705948372615034)
9 Gradient Boosting
梯度上升决策树是另一种常用的算法(基于gradient boosting classifier)。决策树一棵接一棵训练并不断修正之前的错误。当我们训练过多棵树时会产生过拟合,由于训练集数据量很小,这里限制树的棵树为25。
另一种防止过拟合的方式是限制决策树的深度,这里我们讲述的深度限为3。然后我们用GBDT算法来训练,看下是效果是不是比随机森林要好。
10 Ensembling
另一个提升预测精度的方法是混合使用不同的分类器,而不仅仅是一种。通常情况下,模型种类越多,预测得越准确。模型多样化意味着利用更多不同的特征字段、或显著的算法差异性。混合决策树和随机森林提升效果不明显,因为两者本质类似,但是用线性回归和随机森林混合就可能很有效。
混合的前提是所使用的分类器模型在精准度上没有显著差异,否则会使混合后的效果更差。
在本章节中,我们会混合基于某些存在线性关系字段的逻辑回归和基于所有预测因素的梯度上升算法。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38from sklearn.ensemble import GradientBoostingClassifier
import numpy as np
# The algorithms we want to ensemble.
# We're using the more linear predictors for the logistic regression, and everything with the gradient boosting classifier.
algorithms = [
[GradientBoostingClassifier(random_state=1, n_estimators=25, max_depth=3), ["Pclass", "Sex", "Age", "Fare", "Embarked", "FamilySize", "Title", "FamilyId"]],
[LogisticRegression(random_state=1), ["Pclass", "Sex", "Fare", "FamilySize", "Title", "Age", "Embarked"]]
]
# Initialize the cross validation folds
kf = KFold(n_splits=3, random_state=1).split(titanic)
predictions = []
for train, test in kf:
train_target = titanic["Survived"].iloc[train]
full_test_predictions = []
# Make predictions for each algorithm on each fold
for alg, predictors in algorithms:
# Fit the algorithm on the training data.
alg.fit(titanic[predictors].iloc[train,:], train_target)
# Select and predict on the test fold.
# The .astype(float) is necessary to convert the dataframe to all floats and avoid an sklearn error.
test_predictions = alg.predict_proba(titanic[predictors].iloc[test,:].astype(float))[:,1]
full_test_predictions.append(test_predictions)
# Use a simple ensembling scheme -- just average the predictions to get the final classification.
test_predictions = (full_test_predictions[0] + full_test_predictions[1]) / 2
# Any value over .5 is assumed to be a 1 prediction, and below .5 is a 0 prediction.
test_predictions[test_predictions <= .5] = 0
test_predictions[test_predictions > .5] = 1
predictions.append(test_predictions)
# Put all the predictions together into one array.
predictions = np.concatenate(predictions, axis=0)
# Compute accuracy by comparing to the training data.
accuracy = sum(predictions == titanic["Survived"]) / len(predictions)
print(accuracy)
Output:1
0.819304152637
11 Matching Our Changes On The Test Set
现在让我们限提交截止为止学到的内容。首先需要对测试数据集进行同样的加工,生成四个新变量NameLength、FamilySize、Title、FamilyId。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21# First, we'll add titles to the test set.
titles = titanic_test["Name"].apply(get_title)
# We're adding the Dona title to the mapping, because it's in the test set, but not the training set
title_mapping = {"Mr": 1, "Miss": 2, "Mrs": 3, "Master": 4, "Dr": 5, "Rev": 6, "Major": 7, "Col": 7, "Mlle": 8, "Mme": 8, "Don": 9, "Lady": 10, "Countess": 10, "Jonkheer": 10, "Sir": 9, "Capt": 7, "Ms": 2, "Dona": 10}
for k,v in title_mapping.items():
titles[titles == k] = v
titanic_test["Title"] = titles
# Check the counts of each unique title.
print(pandas.value_counts(titanic_test["Title"]))
# Now, we add the family size column.
titanic_test["FamilySize"] = titanic_test["SibSp"] + titanic_test["Parch"]
# Now we can add family ids.
# We'll use the same ids that we did earlier.
print(family_id_mapping)
family_ids = titanic_test.apply(get_family_id, axis=1)
family_ids[titanic_test["FamilySize"] < 3] = -1
titanic_test["FamilyId"] = family_ids
titanic_test["NameLength"] = titanic_test["Name"].apply(lambda x: len(x))
Output:1
2
3
4
5
6
7
8
9
101 240
2 79
3 72
4 21
7 2
6 2
10 1
5 1
Name: Title, dtype: int64
{"O'Sullivan0": 426, 'Mangan0': 620, 'Lindqvist1': 543, 'Denkoff0': 297, 'Rouse0': 413, 'Berglund0': 207, 'Meo0': 142, 'Arnold-Franchi1': 49, 'Chronopoulos1': 71, 'Skoog5': 63, 'Widener2': 329, 'Pengelly0': 217, 'Goncalves0': 400, 'Myhrman0': 626, 'Beane1': 456, 'Moss0': 104, 'Carlsson0': 610, 'Nicholls2': 136, 'Jussila1': 110, 'Jussila0': 483, 'Long0': 632, 'Wheadon0': 33, 'Connolly0': 261, 'Hansen2': 680, 'Stephenson1': 493, 'Davies0': 336, 'Silven2': 359, ...
12 Predicting On The Test Set
创建第二个submission文件。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25predictors = ["Pclass", "Sex", "Age", "Fare", "Embarked", "FamilySize", "Title", "FamilyId"]
algorithms = [
[GradientBoostingClassifier(random_state=1, n_estimators=25, max_depth=3), predictors],
[LogisticRegression(random_state=1), ["Pclass", "Sex", "Fare", "FamilySize", "Title", "Age", "Embarked"]]
]
full_predictions = []
for alg, predictors in algorithms:
# Fit the algorithm using the full training data.
alg.fit(titanic[predictors], titanic["Survived"])
# Predict using the test dataset. We have to convert all the columns to floats to avoid an error.
predictions = alg.predict_proba(titanic_test[predictors].astype(float))[:,1]
full_predictions.append(predictions)
# The gradient boosting classifier generates better predictions, so we weight it higher.
predictions = (full_predictions[0] * 3 + full_predictions[1]) / 4
predictions[predictions <= .5] = 0
predictions[predictions > .5] = 1
predictions = predictions.astype(int)
submission = pandas.DataFrame({
"PassengerId": titanic_test["PassengerId"],
"Survived": predictions
})
这里注意要将predictions用.astype(int)方法转换为整型,负责Kaggle会给你0分。
13 Final Thoughts
完成,现在你有了个大约能得到799分的模型。1
submission.to_csv("kaggle2.csv", index=False)
下一步,变量优化:
- 尝试衍生于
Cabin相关的变量 - 进一步挖掘关于家庭人数的变量——家庭中妇女的数量(比例)是否对整个家庭的存活有关系?
- 乘客的国籍是否会对预测有帮助?
算法优化:
- 尝试混合使用随机森林
- 支持向量机可能在该问题上很有效果
- 也可以试下神经网络
- 使用其他基础分类器来提升可能有效
模型混合:
- majority voting是否比平均概率要好?
titanic这个案例因为数据量较小,很容易产生过拟合,接下来你可以尝试Kaggle上的其他竞赛,它们有更大的数据量和更多的变量可供挖掘分析。
Hope you enjoyed this tutorial, and good luck with the machine learning competitions!